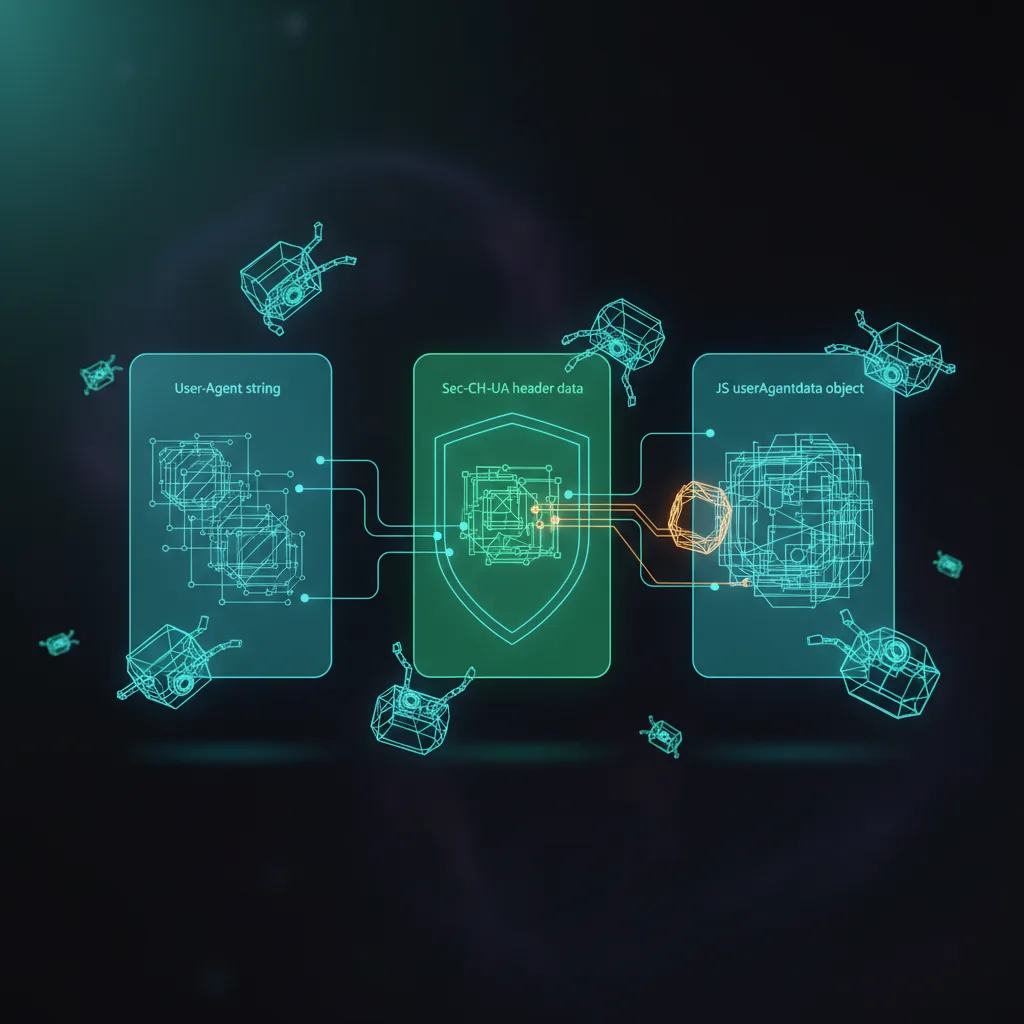
The three sources that must agree
Since Chrome 89+ the browser reports its identity in three places, all generated from one internal source - so on a real browser they always match:
- The UA string -
navigator.userAgentand theUser-Agentheader, now frozen/reduced on Chrome (deliberately trimmed and locked down). - Sec-CH-UA headers -
Sec-CH-UA: "Chromium";v="131", "Not_A Brand";v="24", "Google Chrome";v="131"plus platform and mobile flags on every request. - navigator.userAgentData - the JS API, including
getHighEntropyValues(["platform","platformVersion","architecture","model","fullVersionList"]).
A scraper that edits the User-Agent header but leaves Sec-CH-UA and navigator.userAgentData at their real (or missing) values is instantly incoherent - the three sources contradict each other. Python HTTP clients that send a Chrome UA string but no Sec-CH-UA headers at all are an obvious tell, because real Chrome never omits them.
High-entropy hints and the GREASE trap
Low-entropy hints (brand, mobile, platform) ship on every request. High-entropy hints (full version list, architecture, bitness, model, platform version) are sent only when the server asks for them via the Accept-CH response header - so an anti-bot endpoint can request them and watch how the client answers. The values must agree with each other: Sec-CH-UA-Mobile: ?1 (claiming a mobile device) paired with a desktop platform, or Sec-CH-UA-Arch: "arm" with Sec-CH-UA-Bitness: "32" on a claimed Apple Silicon Mac, are contradictions.
The Sec-CH-UA header also contains a GREASE entry - a deliberately fake brand like "Not_A Brand";v="24" that Chrome adds so servers cannot hardcode the brand list, and whose exact text and punctuation vary by Chrome version. Vendors know the real GREASE patterns per version; a hand-built header with the wrong GREASE string, or with the brands in the wrong order, fails the check. navigator.userAgentData.brands must contain the same GREASE entry as the header.
Why this is hard to spoof by hand
Getting UA-CH right means generating one complete, version-accurate identity across all three surfaces at once: the reduced UA string, every Sec-CH-UA header with the correct GREASE and ordering, and a navigator.userAgentData object whose getHighEntropyValues() returns matching platform/arch/model. Change the Chrome major version and all of them have to move together.
This is why brand-switching and UA spoofing are gated behind engine-level tooling in serious anti-detect browsers - the engine regenerates all three from one config so they cannot drift apart. A managed scraping API solves it the same way: it impersonates a real Chrome build end to end rather than editing one header. Patching just the UA string with a Python requests override is the single most common reason a scraper that "looks like Chrome" still gets blocked.